
이미지 출처 - https://dynamogeeks.com/blog/concurrency-vs-parallelism-a-simplified-explanation
"소프트웨어 시스템의 성능과 확장성은 동시성과 병렬성을 얼마나 효과적으로 활용하느냐에 달려 있습니다. 이 두 개념은 유사하지만 근본적으로 다른 접근법을 제공합니다."
목차
- 동시성(Concurrency)이란?
- 병렬성(Parallelism)이란?
- 동시성과 병렬성의 핵심 차이점
- 실생활 비유로 이해하기
- 프로그래밍 언어별 동시성/병렬성 지원 방식
- 실제 적용 사례
- 주의해야 할 문제점
- 결론
동시성(Concurrency)이란?
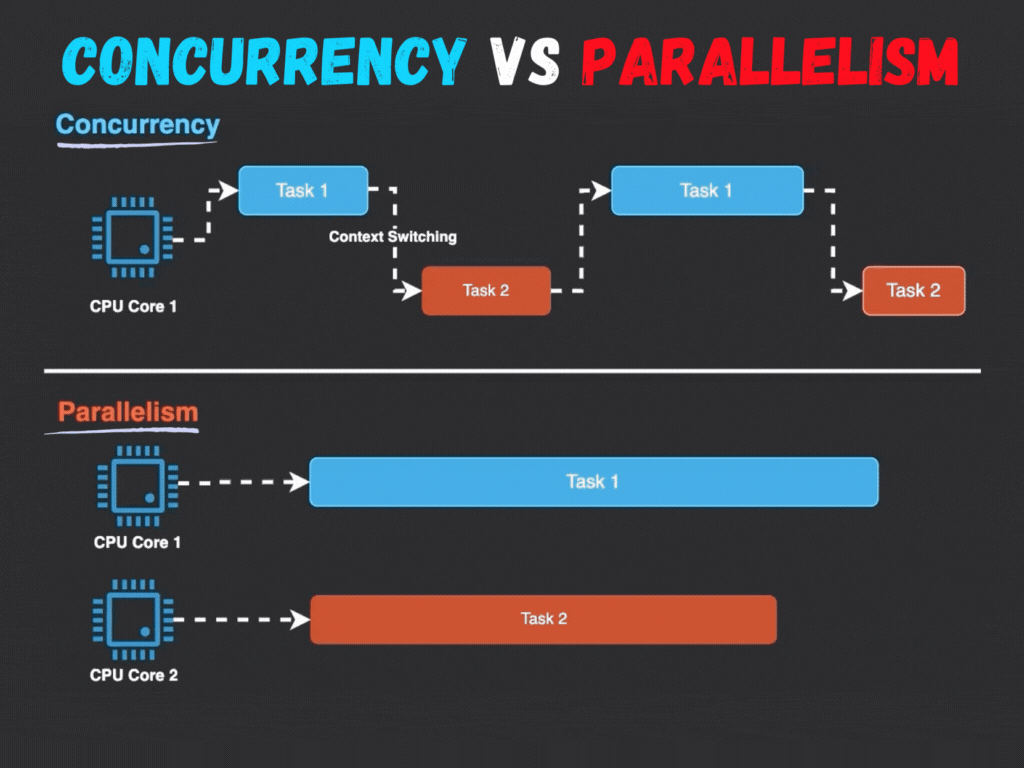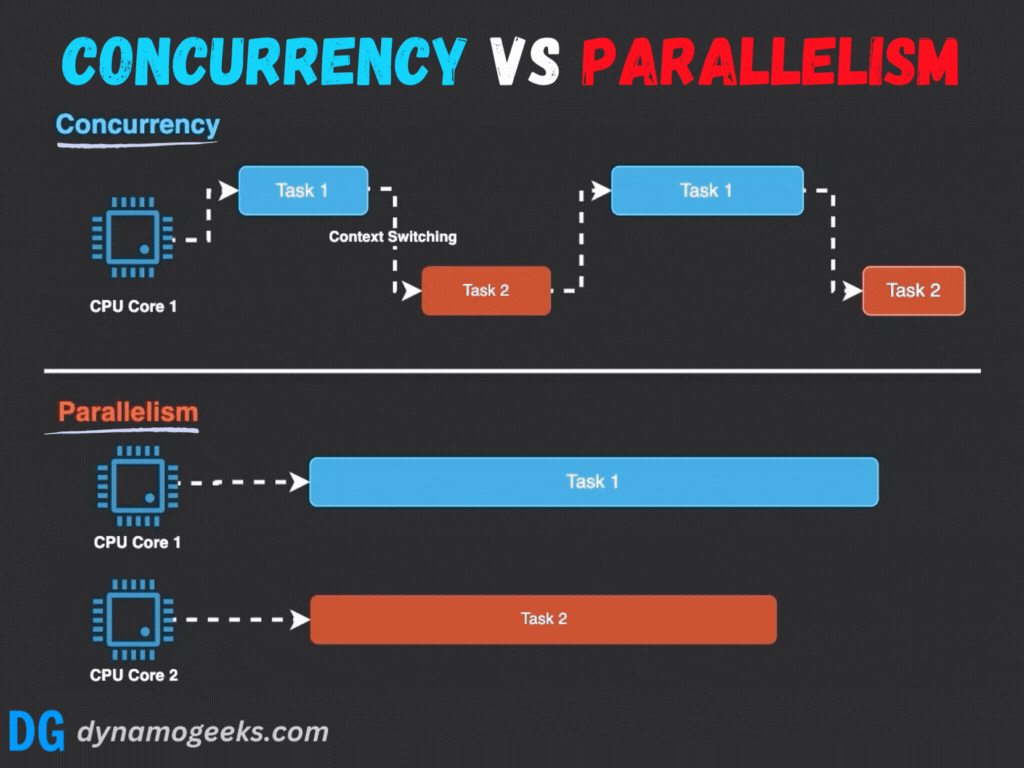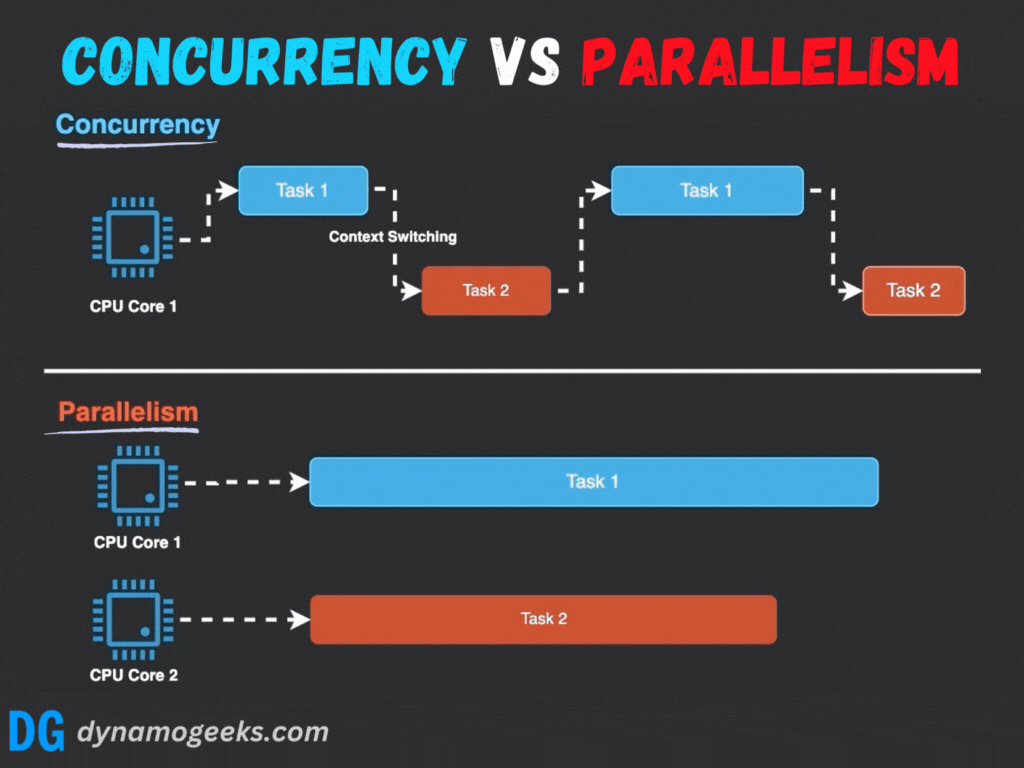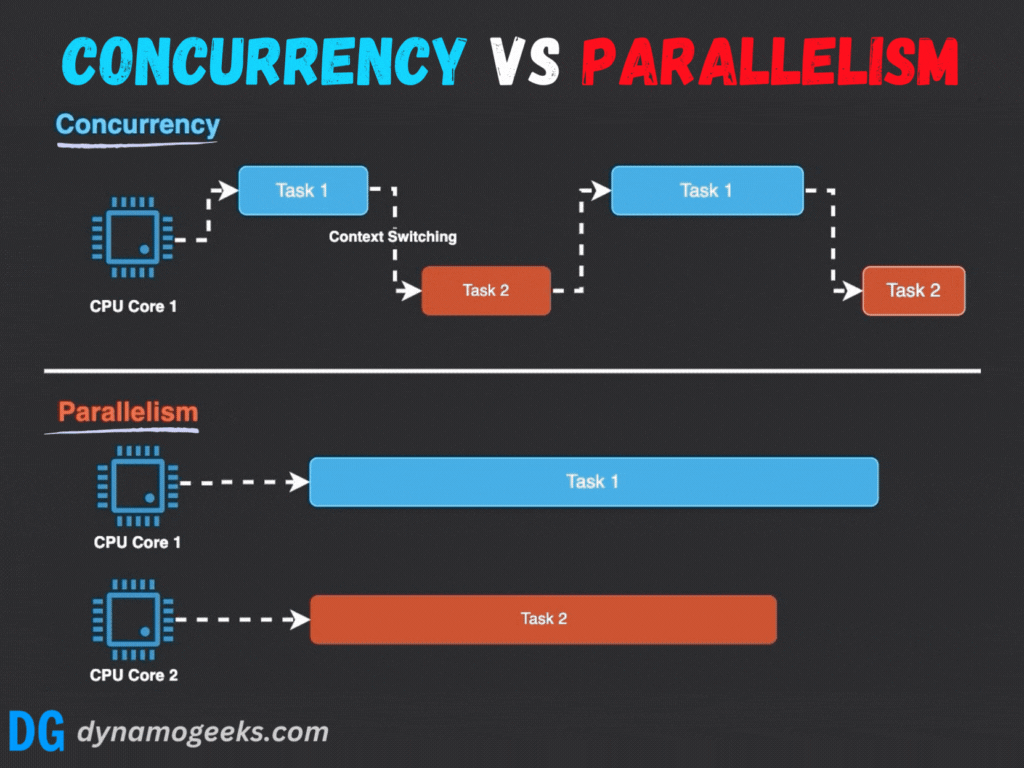
동시성은 여러 작업이 논리적으로 동시에 실행되는 것처럼 보이게 하는 개념입니다. 실제로는 하나의 CPU 코어가 시간을 아주 작은 단위로 분할하여 여러 작업 사이를 빠르게 전환하며 처리합니다. 이 과정에서 컨텍스트 스위칭(Context Switching)이 발생하여 CPU가 한 작업에서 다른 작업으로 전환합니다.
동시성의 핵심 특징:
- 시분할 처리: 하나의 코어가 여러 작업을 번갈아가며 처리
- 논리적 동시 실행: 실제로는 한 번에 하나의 작업만 처리하지만, 사용자 관점에서는 동시에 처리되는 것처럼 느껴짐
- CPU 유휴 시간 활용: I/O 작업이나 네트워크 요청 등으로 CPU가 대기 상태일 때 다른 작업을 처리함으로써 자원 활용도를 높임
동시성이 중요한 상황:
- 웹 서버가 다수의 클라이언트 요청을 처리할 때
- 사용자 인터페이스가 여러 이벤트에 반응해야 할 때
- 네트워크 요청이나 파일 I/O와 같은 대기 시간이 긴 작업을 수행할 때동시성 모델을 통해 백엔드 서버는 수천 개의 동시 연결을 처리할 수 있으며, 하나의 요청이 데이터베이스 응답을 기다리는 동안 다른 요청을 처리할 수 있습니다. 이는 서버 자원을 최대한 효율적으로 활용할 수 있게 해줍니다.
병렬성(Parallelism)이란?
병렬성은 물리적으로 여러 작업을 동시에 실행하는 개념입니다. 이는 여러 개의 CPU 코어나 별도의 처리 장치를 사용하여 실제로 여러 작업을 동시에 수행합니다. 각 코어는 독립적으로 자신에게 할당된 작업을 처리하므로, 작업들이 진정한 의미에서 동시에 실행됩니다.
병렬성의 핵심 특징:
- 물리적 동시 실행: 여러 코어에서 실제로 동시에 작업 처리
- 계산 집약적 작업에 효율적: 복잡한 연산을 병렬화하여 처리 시간 단축
- 성능 향상: 코어 수에 비례해 성능이 향상될 가능성이 있음 (이상적인 경우)
병렬성이 효과적인 상황:
- 대규모 데이터 처리 (빅데이터 분석)
- 과학적 계산 및 시뮬레이션
- 이미지/비디오 처리
- 기계 학습 알고리즘 훈련병렬 처리는a 독립적인 하위 작업으로 나눌 수 있는 작업을 여러 코어에 분산하여 전체 작업 완료 시간을 최소화할 수 있어 고성능 컴퓨팅에 이상적입니다. 예를 들어, 대규모 데이터셋에 대한 맵리듀스(MapReduce) 연산은 여러 머신에 분산하여 병렬로 처리함으로써 훨씬 빠르게 결과를 얻을 수 있습니다.
동시성과 병렬성의 핵심 차이점
동시성과 병렬성은 종종 혼동되지만, 그 개념과 구현 방식에는 명확한 차이가 있습니다:
| 특징 | 동시성(Concurrency) | 병렬성(Parallelism) |
|---|---|---|
| 정의 | 여러 작업을 번갈아가며 처리 | 여러 작업을 동시에 처리 |
| 필요 자원 | 단일 코어로도 구현 가능 | 여러 개의 코어 필요 |
| 목적 | 응답성 향상, 자원 효율성 | 처리 속도 향상, 처리량 증가 |
| 작업 전환 | 컨텍스트 스위칭 발생 | 작업 간 전환 없음 |
| 구조 | 여러 스레드가 같은 코어에서 실행 | 여러 스레드가 각각 다른 코어에서 실행 |
| 이점 | I/O 대기 시간 활용 | 계산 집약적 작업 가속화 |
"동시성은 여러 일을 다루는 것(dealing with multiple things at once)이고, 병렬성은 여러 일을 동시에 하는 것(doing multiple things at once)입니다." - Rob Pike, Go 언어 개발자
실생활 비유로 이해하기
동시성의 예: 주방에서 혼자 여러 요리 준비하기
한 명의 요리사가 여러 요리를 동시에 준비하는 상황을 생각해보세요. 요리사는 파스타의 물이 끓는 동안 야채를 썰고, 소스가 끓는 동안 테이블을 세팅하는 식으로 여러 작업 사이를 전환합니다. 요리사는 한 번에 하나의 작업만 수행하지만, 대기 시간을 효율적으로 활용하여 마치 동시에 여러 요리를 준비하는 것처럼 보입니다.
병렬성의 예: 레스토랑의 여러 요리사
여러 명의 요리사가 각자 다른 요리를 독립적으로 준비하는 레스토랑을 생각해보세요. 한 요리사는 파스타를 만들고, 다른 요리사는 샐러드를 준비하고, 또 다른 요리사는 디저트를 만듭니다. 이들은 실제로 동시에 작업하기 때문에, 총 요리 준비 시간이 크게 단축됩니다.
프로그래밍 언어별 동시성/병렬성 지원 방식
다양한 프로그래밍 언어와 프레임워크는 동시성과 병렬성을 지원하기 위한 고유한 메커니즘을 제공합니다:
Java
// 스레드를 사용한 동시성
Thread thread = new Thread(() -> {
System.out.println("별도의 스레드에서 실행");
});
thread.start();
// ExecutorService를 사용한 병렬 처리
ExecutorService executor = Executors.newFixedThreadPool(4);
for (int i = 0; i < 10; i++) {
int taskId = i;
executor.submit(() -> {
System.out.println("Task " + taskId + " 실행 중, 스레드: " +
Thread.currentThread().getName());
});
}Node.js
// 비동기 콜백을 사용한 동시성
fs.readFile('file.txt', (err, data) => {
if (err) throw err;
console.log(data);
});
console.log('파일 읽기 요청 후 즉시 실행');
// Worker Threads를 사용한 병렬 처리
const { Worker } = require('worker_threads');
const worker = new Worker('./worker.js');
worker.on('message', (result) => {
console.log('워커로부터 결과 수신:', result);
});Go
// 고루틴을 사용한 동시성
func main() {
go func() {
fmt.Println("고루틴에서 실행")
}()
fmt.Println("메인 함수에서 실행")
time.Sleep(time.Second)
}
// 채널을 통한 고루틴 간 통신
func main() {
ch := make(chan string)
go func() {
ch <- "작업 완료!"
}()
result := <-ch
fmt.Println(result)
}Python
# asyncio를 사용한 동시성
import asyncio
async def fetch_data():
print("데이터 가져오는 중...")
await asyncio.sleep(2) # I/O 작업 시뮬레이션
print("데이터 수신 완료!")
return {"data": "값"}
async def main():
result = await fetch_data()
print(result)
asyncio.run(main())
# multiprocessing을 사용한 병렬 처리
from multiprocessing import Pool
def process_chunk(chunk):
# 데이터 처리 로직
return sum(chunk)
if __name__ == "__main__":
data = list(range(1000000))
chunks = [data[i:i+250000] for i in range(0, len(data), 250000)]
with Pool(4) as p:
results = p.map(process_chunk, chunks)
print(f"총합: {sum(results)}")실제 적용 사례
웹 서버의 동시성
현대적인 웹 서버는 수천 개의 동시 연결을 처리하기 위해 동시성 모델을 사용합니다. 예를 들어, Node.js는://node-js의-이벤트-루프
const http = require('http');
const server = http.createServer((req, res) => {
// 데이터베이스 쿼리 같은 비동기 작업
someAsyncOperation(() => {
res.writeHead(200);
res.end('Hello World');
});
});
server.listen(8000);
console.log('서버가 포트 8000에서 실행 중입니다.');이 서버는 싱글 스레드로 동작하지만, 이벤트 루프와 비동기 I/O를 통해 수천 개의 동시 연결을 처리할 수 있습니다. 요청을 처리하는 동안 데이터베이스나 파일 시스템 응답을 기다릴 때, 서버는 다른 요청을 계속 처리할 수 있습니다.
빅데이터 처리의 병렬성
Apache Spark와 같은 빅데이터 프레임워크는 대규모 데이터셋을 병렬로 처리합니다:
// Spark를 사용한 단어 수 계산 예제
val textFile = spark.read.textFile("hdfs://...")
val counts = textFile.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")이 코드는 여러 머신에 분산된 데이터를 병렬로 처리하여 대규모 텍스트 파일의 단어 빈도수를 계산합니다. 각 머신은 데이터의 일부를 독립적으로 처리하고, 결과를 집계합니다.
주의해야 할 문제점
동시성과 병렬성을 활용할 때 발생할 수 있는 여러 문제점이 있습니다:
1. 데드락(Deadlock)
두 개 이상의 프로세스나 스레드가 서로 상대방이 점유한 자원을 기다리며 무한정 대기하는 상태입니다.
// 데드락 가능성 있는 코드
synchronized void transferMoney(Account from, Account to, double amount) {
synchronized(from) {
synchronized(to) {
from.debit(amount);
to.credit(amount);
}
}
}두 스레드가 서로 다른 순서로 계좌에 락을 걸면 데드락이 발생할 수 있습니다.
2. 레이스 컨디션(Race Condition)
둘 이상의 스레드가 공유 데이터에 동시에 접근하여 결과가 접근 순서에 따라 달라지는 상황입니다.
// 레이스 컨디션 예제
let counter = 0;
function increment() {
// 읽기와 쓰기 사이에 다른 스레드가 간섭할 수 있음
const current = counter;
counter = current + 1;
}
// 여러 스레드에서 동시에 호출하면 예상치 못한 결과 발생3. 기아 상태(Starvation)
특정 프로세스나 스레드가 필요한 자원을 계속해서 할당받지 못해 진행이 멈추는 상태입니다.
4. 성능 오버헤드
동시성과 병렬성은 항상 추가적인 오버헤드를 발생시킵니다:
- 컨텍스트 스위칭 비용: 스레드 간 전환 시 CPU 캐시 무효화 및 상태 저장/복원 필요
- 동기화 오버헤드: 락이나 세마포어 사용 시 추가 비용 발생
- 메모리 사용 증가: 각 스레드는 스택 메모리와 상태 정보 유지에 자원 필요
해결 방안
이러한 문제들을 해결하기 위한 몇 가지 접근법:
- 락 순서 일관성 유지: 항상 동일한 순서로 락을 획득하여 데드락 방지
- 원자적 연산 사용: 분할할 수 없는 단일 연산으로 레이스 컨디션 방지
- 락 없는(Lock-Free) 자료구조: CAS(Compare-And-Swap) 같은 기법을 활용한 자료구조 사용
- 스레드 풀 크기 최적화: 시스템 리소스에 맞게 동시 실행 스레드 수 조절
결론
동시성과 병렬성은 현대 백엔드 시스템의 성능, 확장성, 응답성을 향상시키는 핵심 개념입니다. 동시성은 단일 코어에서 여러 작업을 효율적으로 전환하며 처리함으로써 I/O 작업의 대기 시간을 활용하고, 병렬성은 여러 코어에 작업을 분산하여 계산 집약적인 작업의 처리 속도를 높입니다.
시스템 설계 시 고려해야 할 중요한 포인트:
- 작업의 특성 파악: I/O 바운드 작업은 동시성, CPU 바운드 작업은 병렬성이 더 효과적
- 시스템 자원 고려: 가용한 CPU 코어 수와 메모리 용량에 맞게 설계
- 복잡성 관리: 동시성/병렬성 도입은 시스템 복잡도를 높이므로, 필요한 경우에만 사용
- 적절한 추상화: 언어나 프레임워크가 제공하는 고수준 추상화(Promise, Future, async/await 등) 활용
동시성과 병렬성을 적절히 활용하면 시스템 자원을 효율적으로 사용하고 사용자 경험을 향상시킬 수 있지만, 관련 문제점들을 이해하고 적절히 대응하는 것이 중요합니다. 현대 소프트웨어 개발자에게 이 두 개념은 필수적인 도구이며, 이를 마스터하는 것이 고성능 백엔드 시스템 개발의 핵심 역량이라 할 수 있습니다.
참고 자료
'Backend Development' 카테고리의 다른 글
| REST API 완벽 가이드: 개념부터 구현까지 (0) | 2025.05.30 |
|---|---|
| 백엔드 개발자를 위한 효과적인 캐싱 전략 가이드 (4) | 2025.05.30 |
| 로드 밸런싱 완전 정복: 백엔드 개발자를 위한 핵심 가이드 (0) | 2025.05.30 |
| 다중 서버 환경에서의 세션 관리: 스티키 세션과 그 대안들 (4) | 2025.05.29 |
| MySQL Replication 완벽 가이드: 고가용성과 데이터 안정성 확보 (2) | 2025.05.29 |