
의류 검수 AI 시스템을 설계하면서 깨달은 Object Detection 모델 선택의 기준
들어가며
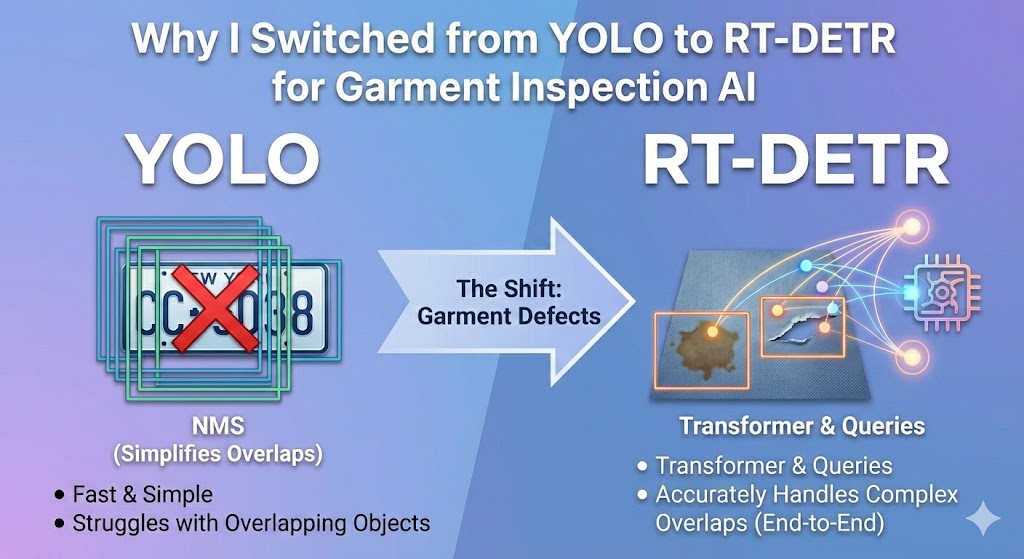
"객체 탐지? 그럼 YOLO지."
솔직히 이게 그동안 내 접근 방식이었다. 차량 번호판 인식 프로젝트에서 YOLO를 써본 이후로, Object Detection이 필요하면 자연스럽게 YOLO를 꺼내 들었다. 빠르고, 정확하고, 레퍼런스도 많으니까.
그런데 최근 의류 품질 검수 AI 시스템을 설계하면서 생각이 바뀌었다. 이 글에서는 왜 YOLO 대신 RT-DETR을 선택했는지, 그 과정에서 알게 된 두 모델의 근본적인 차이를 정리해보려 한다.
과거 경험: 번호판 인식에서의 YOLO
이전에 차량 번호판 인식 시스템을 개발한 적이 있다. 당시 YOLO를 선택했고, 결과는 대만족이었다.
번호판 인식은 "쉬운" 문제다
번호판 검출은 Object Detection 관점에서 상대적으로 단순한 문제다.
| 특성 | 번호판 |
|---|---|
| 형태 | 직사각형으로 고정 |
| 색상 | 명확함 (흰색, 노란색, 녹색) |
| 위치 | 예측 가능 (차량 전후면) |
| 크기 | 상대적으로 일정 |
| 겹침 | 거의 없음 |
이런 특성의 문제에는 빠르고 단순한 모델이 정답이다.
YOLO가 번호판에 최적인 이유
| 모델 | 정확도 | 추론 속도 | 적합성 |
|---|---|---|---|
| YOLOv8n | 95%+ | ~5ms | ✅ 최적 |
| RT-DETR | 96%+ | ~15ms | 과잉 스펙 |
정확도 차이는 1% 미만인데, 속도는 3배 차이. 실시간 처리가 중요한 번호판 인식에서 RT-DETR을 쓰는 건 못 박는데 메스를 쓰는 격이다.
그래서 나도 "Object Detection = YOLO"라는 공식이 자연스럽게 굳어졌다.
새로운 프로젝트: 의류 검수 AI 시스템
그러다 새로운 프로젝트를 맡게 됐다. 중고 의류의 품질을 자동으로 검수하는 AI 시스템이다.
요구사항
- 3000×4000 고해상도 이미지에서 결함 탐지
- 탐지 대상: 오염(얼룩, 때), 손상(구멍, 찢어짐), 부착물(택, 라벨)
- 결함의 정확한 위치와 개수 파악
- S/A/B/F 4단계 등급 판정의 근거 제공
당연히 YOLO로 시작했다. 그런데 AIHub의 "폐의류 재활용 분류 및 선별 데이터"를 분석하다가 흥미로운 걸 발견했다.
AIHub는 결함 탐지에 YOLO가 아닌 RT-DETR을 사용하고 있었다.
왜일까? 이 의문에서 시작된 탐구가 꽤 깊어졌다.
번호판 vs 의류 결함: 문제의 본질이 다르다
두 프로젝트의 탐지 대상을 비교해보면 차이가 명확하다.
| 특성 | 번호판 | 의류 결함 |
|---|---|---|
| 형태 | 직사각형 고정 | 불규칙 (얼룩, 찢어짐) |
| 크기 | 일정함 | 천차만별 (1cm 얼룩 ~ 20cm 손상) |
| 위치 | 예측 가능 | 어디든 발생 |
| 겹침 | 거의 없음 | 자주 겹침 (오염 위에 손상) |
| 개수 | 1~2개 | 여러 개 밀집 가능 |
특히 "겹침" 부분이 핵심이었다. 실제 의류 결함은 이런 식으로 나타난다:
┌─────────────────────────┐
│ ┌─────┐ │
│ │오염 │ │
│ │ ┌───┴──┐ │ ← 얼룩 위에 찢어진 부분
│ └─┤ 손상 │ │
│ └─────┘ │
└─────────────────────────┘이 상황에서 YOLO와 RT-DETR의 동작이 완전히 달라진다.
YOLO의 동작 원리: CNN + Anchor + NMS
YOLO가 어떻게 객체를 탐지하는지 이해하면, 왜 겹친 객체에서 문제가 생기는지 알 수 있다.
1단계: CNN으로 특징 추출
CNN(Convolutional Neural Network)은 작은 필터가 이미지 위를 슬라이딩하면서 특징을 추출한다.
원본 이미지
↓
[3×3 필터가 슬라이딩]
↓
Layer 1: edges, corners (저수준)
↓
Layer 2: textures, patterns (중수준)
↓
Layer 3+: objects (고수준)CNN의 강점은 지역적 패턴을 잘 잡는다는 것이다. 하지만 이미지 전체의 맥락을 파악하려면 레이어를 많이 쌓아야 한다.
2단계: Anchor로 위치 제안
YOLO는 이미지를 그리드로 나누고, 각 셀마다 여러 개의 Anchor(기준 박스)를 배치한다.
이미지를 13×13 그리드로 분할
↓
각 셀에 9개 앵커 배치
↓
총 1,521개 박스에서 객체 여부 예측각 앵커에 대해 예측하는 것:
- 이 앵커에 객체가 있나? (objectness)
- 앵커를 얼마나 조정해야 하나? (Δx, Δy, Δw, Δh)
- 무슨 객체인가? (class)
문제는 하나의 객체에 여러 앵커가 반응한다는 것이다.
3단계: NMS로 중복 제거
NMS(Non-Maximum Suppression)는 중복된 박스를 제거한다.
def nms(boxes, scores, iou_threshold=0.5):
# 1. 신뢰도 순으로 정렬
# 2. 가장 높은 신뢰도 박스 선택
# 3. 나머지와 IoU(겹침 정도) 계산
# 4. IoU가 임계값 이상이면 제거 (중복으로 간주)
# 5. 반복여기서 IoU(Intersection over Union)는 두 박스가 얼마나 겹치는지를 나타낸다.
IoU = 교집합 면적 / 합집합 면적NMS의 치명적 문제: 겹친 객체 제거
여기서 문제가 발생한다. 실제로 겹쳐 있는 서로 다른 객체도 NMS가 하나를 제거해버린다.
두 결함이 겹쳐 있는 경우:
YOLO 예측: bbox 2개 (오염, 손상)
↓
IoU 계산: 0.6 (60% 겹침)
↓
NMS 임계값: 0.5
↓
결과: IoU > 임계값이므로 하나 제거!
↓
최종 출력: 1개만 남음 (오염 OR 손상)이게 번호판에서는 문제가 안 된다. 번호판이 겹칠 일이 없으니까. 하지만 의류 결함에서는 치명적이다.
RT-DETR의 동작 원리: Transformer + Query
RT-DETR은 완전히 다른 방식으로 접근한다.
Transformer: 전체를 한 번에 본다
Transformer는 원래 자연어 처리(NLP)를 위해 만들어졌다. 핵심은 Self-Attention 메커니즘이다.
CNN: 필터가 지역적으로 슬라이딩 → 전체 맥락 파악 어려움
Transformer: 모든 위치가 다른 모든 위치와 관계 계산 → 전역적 이해이미지에 적용하면:
이미지를 패치로 분할
┌────┬────┬────┬────┐
│ P1 │ P2 │ P3 │ P4 │
├────┼────┼────┼────┤
│ P5 │ P6 │ P7 │ P8 │ → Self-Attention으로
├────┼────┼────┼────┤ 모든 패치 간 관계 학습
│ P9 │P10 │P11 │P12 │
├────┼────┼────┼────┤
│P13 │P14 │P15 │P16 │
└────┴────┴────┴────┘Query: Anchor 대신 "질문"
RT-DETR의 혁신은 Object Query다. Anchor 대신 학습 가능한 Query 벡터를 사용한다.
YOLO (Anchor 기반):
"이 위치에 이 크기의 박스가 있나?" × 1,521번
RT-DETR (Query 기반):
"이미지에서 객체 100개 찾아줘"
각 Query가 하나의 객체에 매칭Hungarian Matching: 1:1 매칭
학습 시 Query와 실제 객체를 1:1로 매칭한다. 이게 핵심이다.
예측 (Queries) Ground Truth
┌─────────┐ ┌─────────┐
│ Query 1 │─────────────│ 오염 │
│ Query 2 │─────────────│ 손상 │
│ Query 3 │─────────────│ (없음) │
│ ... │ │ │
└─────────┘ └─────────┘
각 Query가 최대 1개 객체만 담당
→ 중복 예측 자체가 발생하지 않음
→ NMS 불필요!겹친 객체도 분리
앞서 문제가 됐던 "겹친 결함" 상황을 다시 보자.
오염과 손상이 겹쳐 있는 경우:
RT-DETR:
Query 1 → "나는 오염 담당" → 오염 bbox
Query 2 → "나는 손상 담당" → 손상 bbox
각 Query가 독립적으로 예측
NMS 없음
→ 둘 다 정확히 탐지! ✅해상도와 메모리: 현실적인 고려
"그럼 RT-DETR이 무조건 좋은 거 아냐?"
아니다. 인프라 요구사항이 다르다.
Self-Attention의 계산 복잡도: O(n²)
Transformer의 Attention 연산은 입력 길이의 제곱에 비례한다.
입력 해상도별 연산량:
640px → Feature map 20×20 = 400 토큰
Attention: 400² = 160,000 연산
1920px → Feature map 60×60 = 3,600 토큰
Attention: 3,600² = 12,960,000 연산
(81배 증가!)메모리 사용량 비교
| 입력 크기 | YOLO | RT-DETR |
|---|---|---|
| 640px | ~2GB | ~4GB |
| 1920px | ~6GB | ~12GB |
| 3000×4000 | ~15GB | ~80-100GB |
우리 프로젝트의 원본 이미지(3000×4000)를 RT-DETR에 그대로 넣으면 A100 80GB로도 빠듯하다.
현실적인 해결책: SAHI 타일링
원본을 그대로 쓰는 대신, 타일로 분할해서 처리한다.
3000×4000 원본을 1500×2000 타일 6개로 분할
각 타일 → 1920×1920 resize
메모리: ~12GB (타일당)
┌────────┬────────┐
│ Tile 1 │ Tile 2 │
├────────┼────────┤
│ Tile 3 │ Tile 4 │
├────────┼────────┤
│ Tile 5 │ Tile 6 │
└────────┴────────┘SAHI(Slicing Aided Hyper Inference) 라이브러리가 이를 자동화해준다.
from sahi import AutoDetectionModel
from sahi.predict import get_sliced_prediction
model = AutoDetectionModel.from_pretrained(
model_type="rtdetr",
model_path="rtdetr-defect.pt"
)
result = get_sliced_prediction(
image="clothing_3000x4000.jpg",
detection_model=model,
slice_height=1920,
slice_width=1920,
overlap_height_ratio=0.2,
overlap_width_ratio=0.2
)최종 비교: 언제 뭘 써야 하나
정리표
| 구분 | YOLO | RT-DETR |
|---|---|---|
| 아키텍처 | CNN + Anchor | Transformer + Query |
| 후처리 | NMS 필수 | NMS 불필요 |
| End-to-End | ❌ | ✅ |
| 겹친 객체 | 일부 제거 위험 | ✅ 잘 분리 |
| 밀집 객체 | 일부 누락 가능 | ✅ 각 Query가 담당 |
| 추론 속도 | 빠름 | 상대적으로 느림 |
| GPU 메모리 | 적음 | 많음 |
선택 가이드
┌─────────────────────────────────────────────────────────┐
│ │
│ "형태가 고정되고, 겹치지 않는 객체" │
│ └──▶ YOLO │
│ 예: 번호판, 바코드, 로고 │
│ │
│ "불규칙하고, 겹치거나 밀집된 객체" │
│ └──▶ RT-DETR │
│ 예: 의류 결함, 군중, 의료 이미지 │
│ │
│ "실시간 처리가 최우선" │
│ └──▶ YOLO │
│ │
│ "정확도가 최우선, 10 FPS면 충분" │
│ └──▶ RT-DETR │
│ │
└─────────────────────────────────────────────────────────┘우리 프로젝트의 최종 설계
결국 우리 팀은 하이브리드 파이프라인을 채택했다.
┌─────────────────────────────────────────────────┐
│ 의류 검수 AI 파이프라인 │
├─────────────────────────────────────────────────┤
│ │
│ 1단계: RT-DETR (SAHI 타일링) │
│ → 결함 위치/종류 탐지 │
│ → ~150ms (6타일 기준) │
│ │
│ 2단계: Qwen2-VL (필요시) │
│ → 오탐 필터링 + 상세 설명 생성 │
│ │
│ 3단계: 규칙 엔진 │
│ → 메타데이터 + AI 결과 → S/A/B/F 등급 │
│ │
└─────────────────────────────────────────────────┘AIHub 모델 분석에서 RT-DETR 테스트 결과, 의류 장식을 결함으로 오인하는 경우가 있었다. 그래서 VLM(Vision Language Model)을 2차 검증으로 넣어 오탐을 필터링하기로 했다.
결론: 도구는 문제에 맞게
"Object Detection = YOLO"라는 공식은 많은 경우에 맞지만, 전부는 아니다.
번호판처럼 형태가 고정되고 겹치지 않는 문제에는 YOLO가 최적이다. 하지만 의류 결함처럼 불규칙하고 겹치는 문제에는 RT-DETR이 더 나은 선택일 수 있다.
결국 중요한 건 "이 문제의 본질이 뭔가?"를 먼저 파악하는 것이다. 모델은 그 다음이다.
'AI · ML > Computer Vision' 카테고리의 다른 글
| AI 데이터 처리 용어 정리: "증강? 합성? 오버샘플링? 다 뭐가 다른 거야?" (0) | 2026.03.04 |
|---|---|
| AI가 100% 정확하지 않아도 괜찮다: Human-in-the-Loop로 만드는 의류 불량 검수 시스템 (0) | 2026.02.04 |
| PyTorch 하드웨어 의존성 제거하기: Hugging Face Accelerate로 갈아타야 하는 이유 (0) | 2026.01.28 |
| YOLO26: 엣지 디바이스를 위한 차세대 객체 탐지 모델 (0) | 2026.01.19 |